

Rosnąca popularność GraphQL doprowadziła do powstania różnych teorii, które nie zawsze mają wiele wspólnego z prawdą. Jedna z nich zakłada, że język ten zastąpi REST. Tymczasem w rzeczywistości bliżej mu raczej do narzędzia uzupełniającego niż rywala.
Obu technologii można używać przy tworzeniu aplikacji mobilnych i webowych. W tym artykule porównam je, skupiając się głównie na GraphQL i jego roli w projekcie. Wytłumaczę też, kiedy warto z tego języka korzystać.
Kluczowe wnioski
- Tradycyjne architektury sieciowe zmagają się z problemami over-fetching (pobieraniem nadmiarowych danych) oraz under-fetching (wymogiem wielokrotnego odpytywania serwera), co generuje wysokie opóźnienia i nadmierne obciążenie zapytaniami po stronie klienta.
- By rozwiązać te problemy z przesyłaniem danych, warto przejść na warstwę abstrakcji semantycznej opartą na pojedynczych zapytaniach, która skaluje agregację danych w pełnej zależności od wymagań klienta w czasie rzeczywistym.
- Integracja języka GraphQL zastępuje wiele punktów końcowych REST jednolitym, silnie typowanym schematem oraz resolverami, wykorzystując drzewo składni abstrakcyjnej (AST) do walidacji zapytań i przetwarzania operacji przez standardowe protokoły HTTP lub WebSockets.
- Zastosowanie tego środowiska wykonawczego danych eliminuje strukturalne parametry odpowiedzialne za nadmiarowe pobieranie danych, upraszcza spójność kontraktów między różnymi zespołami rozwijającymi aplikacje, a natywne subskrypcje usprawniają dystrybucję zdarzeń w czasie rzeczywistym z wielu źródeł.
Co trzeba wiedzieć o komunikacji i REST API?
Interfejs programowania aplikacji, czyli API (Application Interface Programming) służy do komunikacji pomiędzy dwoma programami lub urządzeniami. Jest to zestaw reguł i protokołów, który określa, w jaki sposób powinna zachodzić wymiana informacji.
Standardowym sposobem komunikacji z serwerem WWW jest protokół HTTP (Hypertext Transfer Protocol). Protokół ten definiuje:
- metody żądań,
- nagłówki,
- statusy,
- treści żądań i odpowiedzi,
- ciasteczka
- mechanizm autoryzacji.
Natomiast REST (REpresentational State Transfer) określa szereg zasad, których należy przestrzegać, aby usługa sieciowa była skalowalna i optymalizowała interakcję pomiędzy klientem a serwerem. Do takich wymagań zaliczamy m.in. jednolity interfejs, bezstanowość czy rozdzielenie klient-serwer. Jeśli wszystkie są spełnione, takie API określa się mianem RESTful.
Jedną z głównych cech tego podejścia jest podział danych na zasoby (resources), które przekładają się na nazwy endpointów.
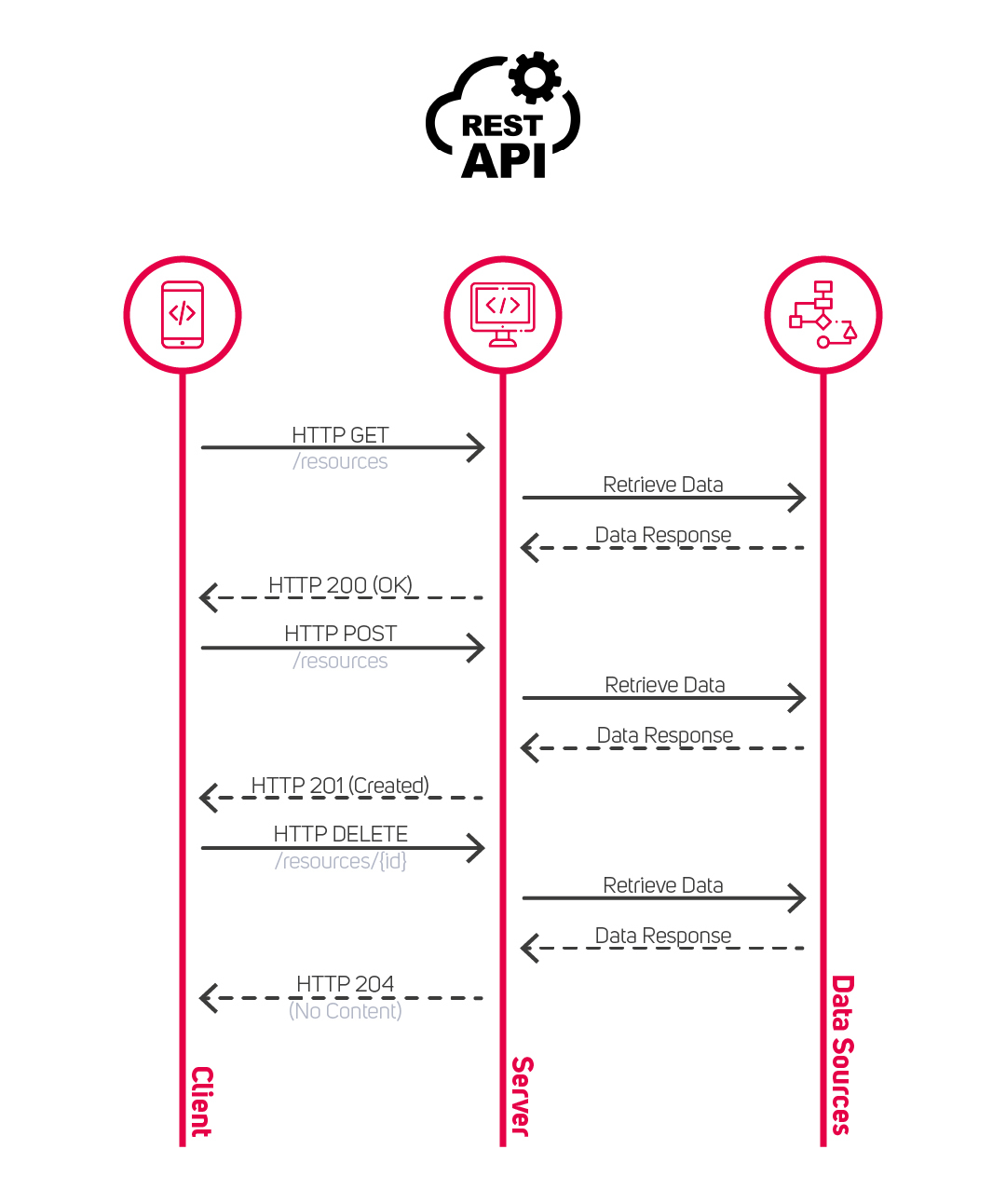
Taki podział na zasoby oraz fakt, że w REST można wysłać tylko jedno zapytanie przy połączeniu HTTP powoduje dwa problemy.
- Nadmiarowe pobieranie (ang. over-fetching)
Zmusza klienta do pobrania danych, których nie potrzebuje, co zwiększa czas przesyłania.
- Niedostateczne pobieranie (ang. under-fetching)
Ma miejsce, gdy jeden endpoint nie dostarcza danych wymaganych przez klienta. Zmusza go to do wysyłania zapytań do kilku endpointów, które również mogą zwracać niepotrzebne dane.
Rozwiązaniem obu tych problemów jest stworzenie nowych endpointów, które będą dopasowane do konkretnych wymagań. Niestety w przypadku rozbudowanych systemów może to być syzyfowa praca.
Wprowadzenie do GraphQL
GraphQL to język zapytań dla API. Zmienia on sposób, w jaki aplikacje pobierają dane i umożliwia uzyskanie potrzebnych informacji za pomocą jednego zapytania. W efekcie nie trzeba borykać się z odpowiedziami z różnych endpointów REST.
Dzięki silnie typowanej schemie GraphQL pomaga definiować relacje między danymi w dowolnej liczbie systemów. W rezultacie można skupić się na tym, do czego dane mają służyć bez zastanawiania się, gdzie są przechowywane.
Jak działa GraphQL?
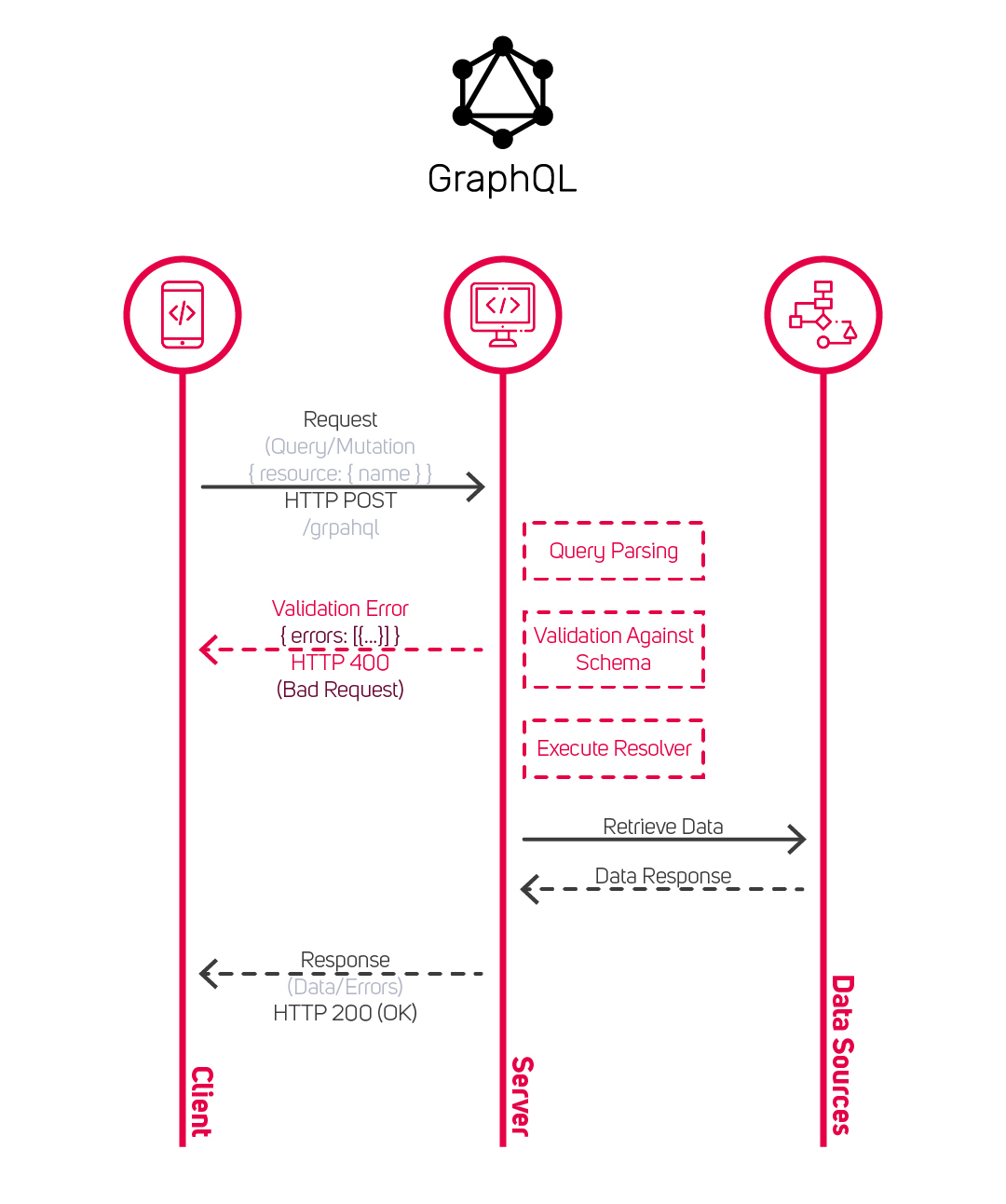
Zobaczmy, co się dzieje, gdy serwer GraphQL otrzymuje żądanie HTTP (zwane również operacją).
- (Query Parsing)
Najpierw serwer wyodrębnia ciąg znaków z operacją GraphQL, analizuje go i przekształca w dokument o strukturze drzewa zwany AST (Abstract Syntax Tree). Dzięki temu można nim wygodniej manewrować. - (Validation Against Schema)
Serwer, korzystając z AST, sprawdza poprawność operacji względem typów i pól w schemie. Jeśli wykrywa jakieś nieprawidłowości (np. żądane pole nie jest zdefiniowane w schemie lub operacja jest źle sformułowana), zwraca błąd i ponownie wysyła go do aplikacji. - (Execute Resolver)
Na podstawie schemy serwer dopasowuje funkcję resolvera dla każdego pola w operacji. Misją tej funkcji jest rozwiązanie pola poprzez przypisanie mu odpowiedniej wartości. Zwykle opiera się ona na danych pochodzących z takich źródeł, jak np. baza danych lub REST API. Te źródła nie muszą znajdować się wewnątrz serwera GraphQL – mogą być źródłami zewnętrznymi. - (Response)
Gdy wszystkie pola operacji są rozwiązane, dane są składane w uporządkowany obiekt JSON, który ma dokładnie taką samą strukturę jak zapytanie. Dane te znajdują się w polu data, natomiast wszystkie błędy w polu errors.
Powyższy proces może przebiegać nieco inaczej w zależności od implementacji specyfikacji GraphQL. Opisuje ona jedynie wymagania techniczne, ale nie podpowiada np. jakich statusów używać w przypadku wykorzystania GraphQL razem z HTTP.
Zanim przejdę do przykładów wykorzystujących GraphQL, przedstawię kilka podstawowych pojęć, które trzeba znać, żeby korzystać z tego języka.
Czym jest schema?
To kluczowa składowa GraphQL. Schema to swego rodzaju kontrakt pomiędzy serwerem a klientem, który określa, co klient może zrobić, a czego nie. Definiuje, jakie operacje są dla niego dostępne oraz jakiego typu odpowiedzi może oczekiwać. Schemę piszemy korzystając z języka SDL (Schema Definition Language).
Składnia tego języka składa się z kilku elementów:
- scalary – najprostsze typy danych, które nie mają żadnych pól. Są to podstawowe jednostki danych służące do opisywania pól w złożonych typach. GraphQL dostarcza kilka wbudowanych opcji: Int, Float, String, Boolean i ID. Istnieje też możliwość tworzenia własnych jednostek.
- typy obiektowe (ang. object types) – składają się z wielu pól, które mają swoje własne typy. Query, Mutation i Subscription to specjalne typy początkowe, od których wychodzą wszystkie możliwe operacje (ang. root types). Ich domyślne nazwy można zmienić.
- interfejsy – abstrakcyjne typy, które pozwalają na zdefiniowanie wspólnych pól dla różnych typów obiektów. Te typy obiektów, które implementują dany interfejs, muszą zawierać wszystkie zdefiniowane w nim pola.
- unie to specjalne typy, które pozwalają na zwrócenie jednego z kilku możliwych typów obiektów. Unie są przydatne, gdy chcesz zwrócić obiekty różnego typu, które nie mają wspólnych pól.
- enumy to specjalne typy, które reprezentują predefiniowane listy możliwych wartości.
- typy wejściowe (ang. input types) – specjalne typy używane do przekazywania złożonych obiektów jako argumentów do operacji.
W artykule stosuję podejście schema-first, co oznacza, że schema tworzona jest ręcznie przed implementacją. Możliwe jest również podejście code-first, w którym schema jest generowana na podstawie kodu. Oba podejścia mają swoje wady i zalety. Tutaj jednak nie będę się na tym skupiać.
Rodzaje operacji
Operacje to inaczej zapytania, które klient wysyła do serwera GraphQL. Określa w nich, jakie dane chce otrzymać.
Kiedy wykonujemy poszczególne operacje?
Query – gdy chcemy pobrać jakieś dane.
Mutation – gdy dodajemy lub aktualizujemy dane.
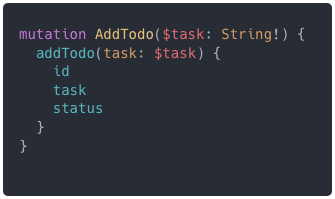
Subscription – gdy chcemy na bieżąco aktualizować dane. Do obsługi tej operacji po stronie serwera zazwyczaj wykorzystuje się inny protokół niż HTTP. Najczęściej jest to websocket. Temat subskrypcji zasługuje na osobny artykuł i tutaj nie będę go poruszać.
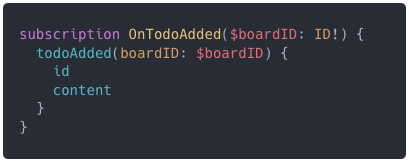
Resolver – funkcja wykonywana na serwerze, która rozwiązuje pole, do którego jest przypisana. Dla każdego typu danych zdefiniowanego w schemie musi istnieć odpowiadający mu resolver.
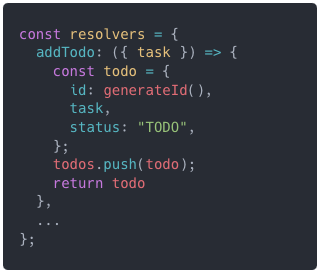
W przykładzie powyżej zdefiniowana jest mapa resolverów z funkcją addTodo, która dodaje zadanie do listy. Aby resolver działał poprawnie, funkcja musi nazywać się tak samo jak typ zdefiniowany w schemie. Do tego mapa resolverów musi być przekazana przy inicjalizacji serwera GraphQL.
Przykładowa aplikacja w REST API i GraphQL
Żeby wytłumaczyć, na czym polega różnica pomiędzy dwoma podejściami, napisałem prostą aplikacją backendową. Najpierw z wykorzystaniem REST API, a następnie w GraphQL.
Umożliwia ona trzy operacje:
- Pobranie pojedynczego zadania po podaniu jego ID.
- Pobranie wszystkich utworzonych zadań.
- Utworzenie nowego zadania.
W celu uproszczenia nie będę używał żadnej bazy danych. Zamiast tego dane będą przechowywane w zwykłej tablicy. Do tego zastosowałem też kilka innych rozwiązań, dzięki którym łatwiej będzie się skupić na kwestiach istotnych z perspektywy tego artykułu.
Podejście z wykorzystaniem REST API
Tak prezentuje się implementacja wspomnianej aplikacji przy podejściu REST z wykorzystaniem danych w formacie JSON.
import express from "express";
import crypto from "crypto";
import bodyParser from "body-parser";
function generateId() {
return crypto.randomBytes(16).toString("hex");
}
const PORT = 4000;
const app = express();
app.use(bodyParser.json());
const todos = [];
app.get("/todos/:id", (req, res) => {
const todo = todos.find((t) => t.id === req.params.id);
if (!todo) {
res.status(404).send("Todo not found");
} else {
res.json(todo);
}
});
app.get("/todos", (req, res) => {
res.json(todos);
});
app.post("/todos", (req, res) => {
const todo = {
id: generateId(),
task: req.body.task,
status: "TODO",
};
todos.push(todo);
res.status(201).json(todo);
});
app.listen(PORT, () => {
console.log(`Example app listening on port ${PORT}`);
});Na co należy tutaj zwrócić uwagę? Przede wszystkim na metody (get i post) wywołane na obiekcie app. Określają one nazwy endpointów oraz reakcje na ich wywołanie.
Komunikacja z serwerem – przykład w JavaScript
W JavaScript najłatwiej pobrać dane to przy użyciu wbudowanej metody fetch.
fetch("http://localhost:4000/todos");Należy pamiętać, że fetch domyślnie ma ustawioną metodę GET.
W przypadku przekazywania wiadomości można użyć tej samej metody tylko trzeba podać nazwę, obiekt i opcje konfigurujące zapytanie HTTP.
const newTodo = { task: "Task 1" };
fetch("http://localhost:4000/todos", {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify(newTodo),
});Podejście z wykorzystaniem GraphQL
Teraz pokażę, jak wyglądałaby taka sama aplikacja przy użyciu GraphQL.
W tym przykładzie również przechowuję zadania w tablicy w kodzie i wykorzystuję format danych JSON.
import express from "express";
import { graphqlHTTP } from "express-graphql";
import { buildSchema, GraphQLError } from "graphql";
import crypto from "crypto";
function generateId() {
return crypto.randomBytes(16).toString("hex");
}
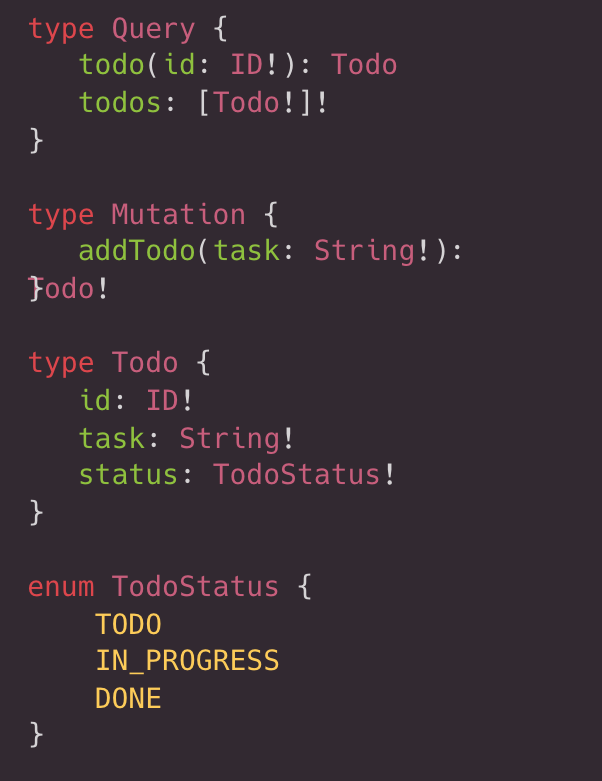
const schema = buildSchema(`
type Query {
todo(id: ID!): Todo
todos: [Todo!]!
}
type Mutation {
addTodo(task: String!): Todo
}
type Todo {
id: ID!
task: String!
status: TodoStatus!
}
enum TodoStatus {
TODO
DONE
IN_PROGRESS
}
`);
const todos = [];
const resolvers = {
todo: ({ id }) => {
const todo = todos.find((todo) => todo.id === id);
if (!todo) {
return new GraphQLError("Todo not found");
}
return todo;
},
todos: () => {
return todos;
},
addTodo: ({ task }) => {
const todo = {
id: generateId(),
task,
status: "TODO",
};
todos.push(todo);
return todo;
},
};
const PORT = 5000;
const app = express();
app.use(
"/graphql",
graphqlHTTP({
schema: schema,
rootValue: resolvers,
graphiql: true,
})
);
app.listen(PORT, () => {
console.log(`Example app listening on port ${PORT}`);
});
W przeciwieństwie do podejścia z REST przy implementacji serwera GraphQL nie definiuje się endpointu dla każdej możliwej operacji. Zamiast tego należy zdefiniować schemę i resolvery, a następnie przekazać je do funkcji graphqlHTTP służącej jako middleware dla wszystkich żądań kierowanych do ścieżki /graphql (przyjęło się stosować taką nazwę, ale można ją zmienić).
Dodatkowo implementacja express-graphql pozwala na włączenie graphiQL, co umożliwia interaktywne testowanie dostępnych operacji.
W produkcyjnym kodzie zazwyczaj stosuje się narzędzia i techniki, które pomagają przy rozwoju serwera GraphQL. Przykładowo schema zazwyczaj znajduje się w osobnym pliku (np. schema.graphql) dzięki czemu edytor kodu może podświetlać składnię i wykrywać błędy.
Komunikacja z serwerem – przykład w JavaScript
Tak jak w przypadku REST, w GraphQL również najłatwiej pobrać dane przy użyciu języka JavaScript i wbudowanej metody fetch.
Różnica polega na zdefiniowaniu zapytania (w tym przypadku getTodos), które piszemy w specjalnym języku zapytań GraphQL. Jest to inny język niż ten, który służy do projektowania schemy. W pewnym stopniu przypomina JSON.
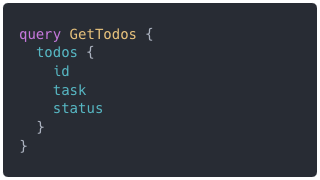
const getTodos = `
query {
todos {
id
task
status
}
}
`;
fetch("http://localhost:5000/graphql", {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({ query: getTodos }),
});Mutację wykonuje się analogicznie do zapytania.
const addTodo = `
mutation AddTodo($task: String!) {
addTodo(task: $task) {
id
task
status
}
}
`;
const variables = {
task: "Task 1",
};
fetch("http://localhost:5000/graphql", {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({
query: addTodo,
variables,
}),
});
W przykładzie przekazuję też obiekt zmiennych (ang. variables). Można w nim zamieścić argumenty wymagane w operacjach.
Aby ułatwić korzystanie z GraphQL API, zazwyczaj korzysta się z gotowych klientów, czyli narzędzi do wykonywania zapytań np. Apollo Client.
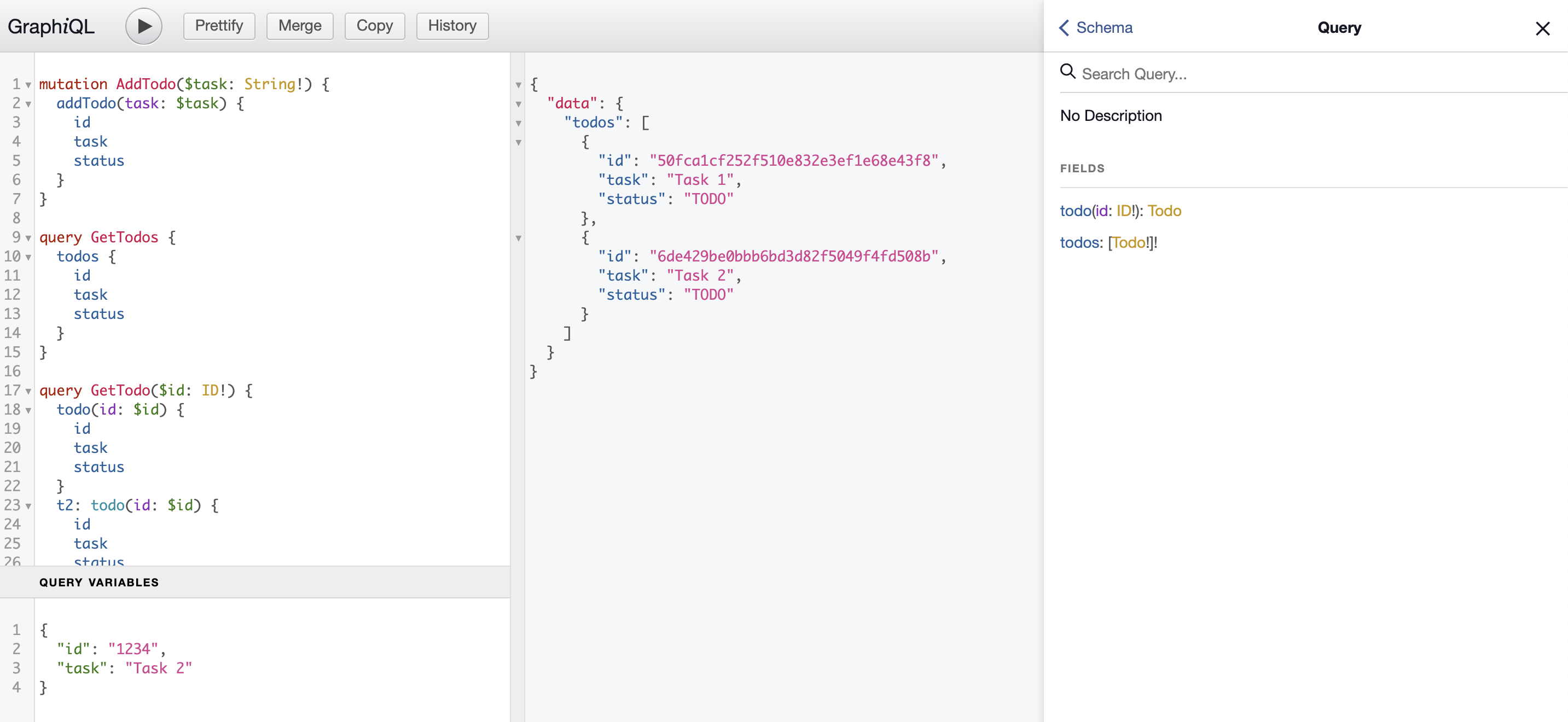
Testowanie zapytań z GraphiQL
Większość implementacji (o ile nie wszystkie) ma wbudowane interaktywne środowisko do testowania zapytań GraphQL bezpośrednio z przeglądarki.
W przypadku express-graphql masz do dyspozycji np. GraphiQL. Warto od tego zacząć, gdy chcesz stworzyć operację do GraphQL API lub zapoznać się z jego dokumentacją.
Warto wiedzieć, że GraphiQL nie jest jedyną dostępną opcją. Bardziej rozbudowaną alternatywę stanowi GraphQL Playground i Apollo Sandbox.
Korzyści ze stosowania GraphQL
GraphQL oferuje wiele zalet, takich jak:
- Efektywne pobieranie danych – pozwala klientom precyzyjnie określić, jakie dane są potrzebne, co eliminuje problem nadmiarowych danych, które są często zwracane przez REST API.
- Silne typowanie – każda odpowiedź GraphQL jest przewidywalna, ponieważ każde pole i każdy typ danych są zdefiniowane w schemie.
- Introspekcja API – schema GraphQL może być pobierana na bieżąco. To pozwala łatwo sprawdzić, jakie zapytania są możliwe.
- Zapytania do wielu źródeł danych – GraphQL umożliwia tworzenie zapytań do wielu źródeł danych jednocześnie, co ułatwia agregację danych z różnych miejsc.
- Obsługa zdarzeń w czasie rzeczywistym przy użyciu subskrypcji – umożliwia aktualizację po stronie klienta tylko wtedy, gdy dane ulegają zmianie.
- Ewolucyjność – GraphQL pozwala na dodawanie nowych pól i typów do API bez wpływu na istniejące zapytania. Starsze pola mogą być oznaczone jako przestarzałe i ukryte przed narzędziami introspekcji.
- Wsparcie dla różnych platform – istnieje wiele bibliotek dla różnych języków i platform, które ułatwiają pracę z GraphQL, zarówno na serwerze, jak i po stronie klienta.
GraphQL vs RESTful – co jest lepsze?
Nie da się jednoznacznie odpowiedzieć na to pytanie. GraphQL ma potencjał, aby być lepszym rozwiązaniem pod kątem skalowalności aplikacji na wielu platformach. Jest przy tym bardziej wydajny.
Z drugiej strony łatwo przy nim popełnić błędy, zwłaszcza jeśli nie ma się zbyt dużego doświadczenia. Najprostszym przykładem jest brak stosowania zabezpieczeń przed wielokrotnością zagnieżdżeń:

W powyższym przykładzie zalogowany użytkownik ma przyjaciół, a przyjaciele mają swoich przyjaciół itd.
Jeśli teraz nie wprowadzę żadnego mechanizmu ograniczającego ilość zagnieżdżeń, tym samym daję potencjalną furtkę na atak DDoS jednym zapytaniem.
Na szczęście w odpowiedzi na tego typu problemy powstały narzędzia, które potrafią ograniczyć potencjalne nadużycie API. Niemniej chciałem pokazać, że gdy brakuje nam wiedzy, łatwo wystawić się na atak.
Poza tym GraphQL nie ma tak rozwiniętej społeczności oraz narzędzi jak REST. Może to utrudniać znalezienie odpowiedzi na pewne problemy w projekcie.
Warto też pamiętać, że GraphQL nie jest wrogiem REST API, a raczej narzędziem uzupełniającym. Dlatego nic nie stoi na przeszkodzie, aby zacząć od podejścia REST, a potem, gdy zajdzie taka potrzeba, potraktować stworzony serwis jako źródło danych (data source), a GraphQL jako warstwę abstrakcji służącą za interfejs.
Jeśli zatem wahasz się, od którego rozwiązania zacząć, to sugeruję REST. Dlaczego? Jest prostszy i więcej osób rozumie jak działa, a w razie potrzeby możesz później połączyć go z językiem GraphQL. Nie zawsze będzie to jednak dobre wyjście.
Kiedy lepiej zacząć od GraphQL?
W dwóch wyjątkowych sytuacjach warto rozważyć GraphQL jako początkowe podejście:
- Gdy nad aplikacją pracuje wiele zespołów (np. w przypadku wieloplatformowości). Wtedy GraphQL daje możliwość ustalenia schemy i pozwala zmniejszyć ilość czasu potrzebnego na komunikację.
- Gdy projekt w dużym stopniu opiera się na danych w czasie rzeczywistym. Dzięki subskrypcjom możliwe jest uproszczenie komunikacji.
Zawsze należy mieć na uwadze doświadczenie zespołu i specyficzne problemy wynikające z charakterystyki naszego projektu. Warto się upewnić, że GraphQL oferuje na nie gotowe rozwiązania.
Przydatne linki
W artykule pominąłem fakt, że przy implementacji GraphQL korzysta się z różnych narzędzi wspomagających pracę. Jeśli zainteresował cię ten temat, sprawdź platformę Apollo, a jeśli używasz języka TypeScript zobacz narzędzia The Guild.
- Designing Your First GraphQL Schema – wskazówki przydatne przy projektowaniu schemy.
- Subscriptions and Live Queries – Real Time with GrapQL – zerknij tu, jeśli potrzebujesz informacji na temat subskrypcji i ich implementacji po stronie serwera.
- A Guide to GraphQL Errors – informacje o problemach związanych z obsługą błędów.
- GraphQL Schema Design: Building Evolvable Schemas – stąd dowiesz się, jak stosować podejście ewolucyjne do API zamiast wersjonowania.
- GraphQL Voyager to przydatne narzędzie do wizualizacji połączeń w schemie.
- GraphQL: The Documentary – tu znajdziesz historię powstawania GraphQL.



